前言
以前对 Glide 的认知一直停留在一行代码就可以完成图片加载,现在就来尝试探索下这一行代码下,内部到底做了些什么。本文基于Glide 4.8.0。
查阅官方文档发现 Glide 主要有以下优点:
- 调用方便,一行代码
- 无代码侵入,直接使用 ImageView 即可
- 扩展性强,快速集成 OkHttp 等等
- 支持 Gif 图片加载
- 生命周期及网络连接变化时自动管理请求
基本使用
使用 Glide 加载网络图片可以简单使用以下一行代码搞定。
Glide.with(this).load(URL).into(imageView) |
如果需要指定默认图、错误图等,那么可以新建一个 RequestOptions 进行设置。
val options = RequestOptions().apply { |
还有很多其它用法就不展开了。
基本概念
在分析源码前,需要先了解以下几个类,以便于后续进行分析。
Target
Glide 通知外界加载过程的接口,主要有四个回调方法 onLoadStarted、onResourceReady、onLoadCleared、onLoadFailed 。
Encoder
编码器,用于将数据写入到某种持久化数据存储中。
Decoder
解码器,用于从某种持久化数据存储中读取数据。
Transcoder
转码器,用于将一种资源类型转换为另一种资源类型,比如 Bitmap 转换为 BitmapDrawable 等等。
Transformation
资源转换,不同于转码器,这个属于同种资源转换,比如进行裁减等等。
DataRewinder
倒带器(类似磁带回放),用于将数据的读取位置进行重置。比如读取了图片头后,又需要将其编码存储到文件中,这时就需要重置。
ModelLoaderFactory
数据模型加载器工厂,用于构建具体的数据模型加载器,基本都以对应 ModelLoader 类的内部类存在。
ModelLoader
数据模型加载器,用于将任意复杂的数据模型转换为具体的数据类型,比如将 String 转换为 InputSteam 等。
public interface ModelLoader<Model, Data> { |
LoadData
加载资源的 Key 和用于加载该资源的 DataFetcher 包装对象。
class LoadData<Data> { |
DecodePath
一条解码路径,dataClass => resourcesClass => transcodeClass,如 ByteBuffer => GifDrawable => Drawable。
LoadPath
多条解码路径(内部保证 dataClass、resourcesClass、transcodeClass 一致),内部包含若干个 DecodePath。
RequestManager
请求管理器,控制当前 Activity 或者当前应用所有请求的加载与暂停(会根据生命周期或者网络连接变化进行控制),每个 Activity 都可以拥有一个实例,应用级还可以拥有一个实例。
RequestManagerRetriever
请求管理器寻回者,用于新建一个 RequestManager 实例或者从 Activity 和 Fragment 中寻回已经存在的实例。
RequestBuilder
一个泛型类,可以处理泛型资源类型的选项设置和开始加载,也就是构建 Request。
Request
请求其用于加载资源到 Target ,一共就三个子类:
SingleRequest 对应普通的请求
ThumbnailRequestCoordinator 对应带缩略图的请求
ErrorRequestCoordinator 对应带错误请求的请求
Engine
负责开始加载以及管理缓存(两级内存缓存以及磁盘缓存)
源码分析
Glide.with
Glide.with 提供了好多个重载方法,这里以参数为 FragmentActivity 的方法为例。

public static RequestManager with(@NonNull FragmentActivity activity) { |
Glide.getRetriever
该方法用于获取到一个 RequestManagerRetriever 实例。
private static RequestManagerRetriever getRetriever(@Nullable Context context) { |
由于最初 Glide 实例还未创建,因此会执行 checkAndInitializeGlide 方法创建 Glide 实例并进行初始化。
private static void initializeGlide(@NonNull Context context, @NonNull GlideBuilder builder) { |
这里会涉及到自定义 GlideModule,这个可以根据官方文档编写,这里不关注,先跟主线,该方法核心就是 GlideBuilder.build 创建 Glide 实例。
Glide build(@NonNull Context context) { |
如果自定义 GlideModule 中没有单独设置那么 sourceExecutor、diskCacheExecutor 等都使用默认值。这里创建了 Engine、RequestManagerRetriever 实例,最终创建了 Glide 实例。
Glide(...) { |
注册表类 Registry 内部还包含了很多个注册表,结构如下。
public class Registry { |
内部七个注册表分别对应 Glide 实例创建时注册的七种类型。注册表输入如下:
ModelLoaderRegistry
| ModelClass | DataClass | ModelLoaderFactory |
|---|---|---|
| Bitmap | Bitmap | UnitModelLoader.Factory |
| GifDecoder | GifDecoder | UnitModelLoader.Factory |
| File | ByteBuffer | ByteBufferFileLoader.Factory |
| File | InputStream | FileLoader.StreamFactory |
| File | ParcelFileDescriptor | FileLoader.FileDescriptorFactory |
| File | File | UnitModelLoader.Factory |
| int | InputStream | ResourceLoader.StreamFactory |
| int | ParcelFileDescriptor | ResourceLoader.FileDescriptorFactory |
| int | Uri | ResourceLoader.UriFactory |
| int | AssetFileDescriptor | ResourceLoader.AssetFileDescriptorFactory |
| Integer | InputStream | ResourceLoader.StreamFactory |
| Integer | ParcelFileDescriptor | ResourceLoader.FileDescriptorFactory |
| Integer | Uri | ResourceLoader.UriFactory |
| Integer | AssetFileDescriptor | ResourceLoader.AssetFileDescriptorFactory |
| String | InputStream | DataUrlLoader.StreamFactory |
| String | InputStream | StringLoader.StreamFactory |
| String | ParcelFileDescriptor | StringLoader.FileDescriptorFactory |
| String | AssetFileDescriptor | StringLoader.AssetFileDescriptorFactory |
| Uri | InputStream | DataUrlLoader.StreamFactory |
| Uri | InputStream | HttpUriLoader.Factory |
| Uri | InputStream | AssetUriLoader.StreamFactory |
| Uri | InputStream | MediaStoreImageThumbLoader.Factory |
| Uri | InputStream | MediaStoreVideoThumbLoader.Factory |
| Uri | InputStream | UriLoader.StreamFactory |
| Uri | InputStream | UrlUriLoader.StreamFactory |
| Uri | ParcelFileDescriptor | AssetUriLoader.FileDescriptorFactory |
| Uri | ParcelFileDescriptor | UriLoader.FileDescriptorFactory |
| Uri | AssetFileDescriptor | UriLoader.AssetFileDescriptorFactory |
| Uri | File | MediaStoreFileLoader.Factory |
| Uri | Uri | UnitModelLoader.Factory |
| URL | InputStream | UrlLoader.StreamFactory |
| GlideUrl | InputStream | HttpGlideUrlLoader.Factory |
| byte[] | InputStream | ByteArrayLoader.StreamFactory |
| byte[] | ByteBuffer | ByteArrayLoader.ByteBufferFactory |
EncoderRegistry
| DataClass | Encoder |
|---|---|
| ByteBuffer | ByteBufferEncoder |
| InputSteam | SteamEncoder |
ResourceEncoderRegistry
| DateClass | ResourceEncoder |
|---|---|
| Bitmap | BitmapEncoder |
| InputSteam | BitmapDrawableEncoder |
| GifDrawable | GifDrawableEncoder |
ResourceDecoderRegistry
| Bucket | DataClass | ResourceClass | ResourceDecoder |
|---|---|---|---|
| Bitmap | ByteBuffer | Bitmap | ByteBufferBitmapDecoder |
| Bitmap | InputSteam | Bitmap | StreamBitmapDecoder |
| Bitmap | ParcelFileDescriptor | Bitmap | VideoDecoder |
| Bitmap | AssetFileDescriptor | Bitmap | VideoDecoder |
| Bitmap | ByteBuffer | Bitmap | ByteBufferBitmapDecoder |
| BitmapDrawable | ByteBuffer | BitmapDrawable | BitmapDrawableDecoder |
| BitmapDrawable | InputStream | BitmapDrawable | BitmapDrawableDecoder |
| BitmapDrawable | ParcelFileDescriptor | BitmapDrawable | BitmapDrawableDecoder |
| Gif | InputSteam | GifDrawable | StreamGifDecoder |
| Gif | ByteBuffer | GifDrawable | ByteBufferGifDecoder |
| legacy_append | Uri | Drawable | ResourceDrawableDecoder |
| legacy_append | Uri | Bitmap | ResourceBitmapDecoder |
| legacy_append | File | File | FileDecoder |
| legacy_append | Drawable | Drawable | UnitDrawableDecoder |
DataRewinderRegistry
| DataClass | DataRewinder | DataRewinder.Factory |
|---|---|---|
| InputStream | InputStreamRewinder | InputStreamRewinder.Factory |
| ByteBuffer | ByteBufferRewinder | ByteBufferRewinder.Factory |
TranscoderRegistry
| ResourceClass | TranscodeClass | ResourceTranscoder |
|---|---|---|
| Bitmap | BitmapDrawable | BitmapDrawableTranscoder |
| Bitmap | byte[] | BitmapBytesTranscoder |
| Drawable | byte[] | DrawableBytesTranscoder |
| GifDrawable | byte[] | GifDrawableBytesTranscoder |
ImageHeaderParserRegistry
| ImageHeaderParser |
|---|
| DefaultImageHeaderParser |
| ExifInterfaceImageHeaderParser |
至此 getRetriever 方法结束了,返回一个新建的 RequestManagerRetriever 实例。
RequestManagerRetriever.get
该方法用于获取到一个 RequestManager 实例。
public RequestManager get(@NonNull FragmentActivity activity) { |
如果当前在子线程执行,那么直接当做 Application 进行处理,否则调用 supportFragmentGet 尝试去获取一个 RequestManager。
private RequestManager supportFragmentGet(Context context, FragmentManager fm, |
这里会涉及到通过监听生命周期来达到开启暂停加载图片,具体细节如下。
private SupportRequestManagerFragment getSupportRequestManagerFragment(...) { |
get 方法其实就是向当前 Activity 添加一个看不见的 SupportRequestManagerFragment,主要看下该 Fragment 内部实现。
public class SupportRequestManagerFragment extends Fragment { |
SupportRequestManagerFragment 重写了 Fragment 的生命周期方法,增加调用 ActivityFragmentLifecycle 对应方法,进而通知 LifecycleListener,不过问题来了,addListener、removeListener 在哪里调用了?经过查询只会在 RequestManager 中被调用。
class RequestManager { |
也就是每当 Fragment 生命周期变化时,都会通知与之绑定的 RequestManager 因此也就可以根据生命周期控制加载和暂停。
RequestManager.load
RequestManager.load 有以下好几个重载方法,这里以参数为 String 的方法为例。
public RequestBuilder<Drawable> load(@Nullable String string) { |
asDrawable 内部会创建一个 RequestBuilder 实例返回。
public RequestBuilder<TranscodeType> load(@Nullable String string) { |
loadGeneric 将数据源(这里是请求地址)进行存储,然后就返回自身。
RequestBuilder.into
into 方法有以下好几个重载方法:

暂时只关注下参数为 ImageView 类型的方法。
public ViewTarget<ImageView, TranscodeType> into(@NonNull ImageView view) { |
接着调用 GlideContext.buildImageViewTarget 创建 Target 实例。
public <X> ViewTarget<ImageView, X> buildImageViewTarget(ImageView imageView, Class<X> transcodeClass) { |
这里由于前面调用了 asDrawable 因此 transcodeClass 为 Drawable,最终会创建一个 DrawableImageViewTarget 返回。继续跟进 into 方法。
private <Y extends Target<TranscodeType>> Y into( |
buildRequest 用于构建 Request 实例。
private Request buildRequest(...) { |
可以看到如果没有设置错误请求或者缩略图,那么最终创建的就是 SingleRequest 实例,初始状态为 PENDING。
track 主要用于追踪 Target、Request 以及开启请求。
void track(@NonNull Target<?> target, @NonNull Request request) { |
如果当前 RequestManager 没有暂停,那么开始请求,否则添加了等待队列中去,等待后续开始。
public void begin() { |
如果长宽已经被指定,那么直接调用 onSizeReady 继续下个流程。如果没有被指定,那么首先获取大小,获取后也会再调用 onSizeReady 继续下个流程。
接着如果图片正在加载,或者正在等待获取大小(获取大小方法为如果 View 还没进行测量,就设置一个 onPreDrawListener 等待测量完成后计算,如果设置了 wrap_content 那么会按照屏幕大小加载)回调 onLoadStarted 展示占位图片。
public void onSizeReady(int width, int height) { |
当加载的尺寸确定了以后就设置当前 Request 状态为 Running ,然后使用 Engine 去加载该图片。注:上面也说过 Engine 主要负责开启加载以及管理活动的或缓存的资源。
public <R> LoadStatus load(...) { |
首先从正活跃的资源缓存中获取资源,如果获取不到再从内存缓存中获取资源,还是获取不到则创建 EngineJob 实例前去加载。由于前面两级内存缓存还没内容,因此先看 EngineJob.start 。
public void start(DecodeJob<R> decodeJob) { |
最终在线程池中执行了 DecodeJob ,跟进其 run 方法。
public void run() { |
内部就简单处理了下取消的情况,然后又调用了 runWrapped。
private void runWrapped() { |
runWrapped 为 DecodeJob 的控制中枢,它决定了每一步需要执行的操作。
RESOURCE_CACHE
初始时 runReason 为 INITIALZIE,获取到的 nextStage 为 RESOURCE_CACHE 表明从磁盘缓存中读取转化过的资源,对应ResourceCacheGenerator 类。根据 runGenerators 的逻辑,跟进其 startNext 方法。
public boolean startNext() { |
这个方法主要是从磁盘缓存中查询是否存在转换后的图片资源,如果存在再进行解码,这里先跳过,后续分析缓存的时候再看。首次该方法由于没有缓存,最终会返回 false。接着会进入下一步。
DecodeHelp.getCacheKeys
getCacheKeys 用于获取该数据源类型所有可能的缓存 Key。
List<Key> getCacheKeys() { |
首先从注册表中获取所有支持该数据源转换的 ModelLoader ,然后分别让它们去构建 LoadData,最后获取所有构建完成的 LoadData.sourceKey 返回。由于一个 ModelLoader 可以会依赖于另一个 ModelLoader 因此获取所有支持该数据源转换的 ModelLoader 较为复杂。具体细节代码如下:
// Registry.java |
实际是从 ModelLoaderRegistry 中去获取所有支持该类型的 ModelLoader。
public <A> List<ModelLoader<A, ?>> getModelLoaders( A model) { |
这段代码意思很简单,首先获取所有支持该数据源类型的 ModelLoader 列表,然后过滤支持当前数据源的 ModelLoader,为什么需要过滤?原因是有些 ModelLoader 虽然说支持数据源类型为 String,但是它对这个字符串也有着要求,比如其只支持以 data:image 开头的字符串,那么其实核心还是在 getModelLoadersForClass 这个方法中。
private synchronized <A> List<ModelLoader<A, ?>> getModelLoadersForClass(Class<A> modelClass) { |
这里有一层缓存,不过初始时并不存在,因此会通过 MultiModelLoaderFactory 去获取支持该数据源类型的 ModelLoader。
注册关系为 Registry => ModelLoaderRegistry => MultiModelLoaderFactory,所有注册的 ModelLoaderFactory 其实都在 MultiModelLoaderFactory 里面。
synchronized <Model> List<ModelLoader<Model, ?>> build( Class<Model> modelClass) { |
上述代码其实就是过滤所有支持该数据源的 ModelLoader,但是复杂就在于上述注释一处,某些 ModelLoaderFactory 在构建具体的 ModelLoader 实例时又会去调用 MultiModelLoaderFactory 的以下一个重载 build 方法,这里以 StringLoader.StreamFactory 举例说明。
public static class StreamFactory implements ModelLoaderFactory<String, InputStream> { |
上述代码又会去寻找所有支持将 Uri 转换为 InputSteam 的 ModelLoader,那么继续跟进另一个 build 方法。
public synchronized <Model, Data> ModelLoader<Model, Data> build(Class<Model> modelClass, |
大体上与一开始的 build 方法类似,不同点只在于最终如果查询到多个 ModelLoader 那么会封装成一个 MultiModelLoader 进行返回。这里可能会递归调用。举个例子,如果起始时数据源类型为 String,那么最终就会寻找到如下 ModelLoader 集。
String
=> DataUrlLoader(String => InputSteam)
=> StringLoader(String => InputSteam Recur to Uri => InputSteam)
=> DataUrlLoader(Uri => InputSteam)
=> HttpUriLoader(Uri => InputSteam Recur to GlideUrl => InputSteam)
=> HttpGlideUrlLoader(GlideUrl => InputSteam)
=> AssetUriLoader(Uri => InputSteam)
=> MediaStoreImageThumbLoader(Uri => InputSteam)
=> MediaStoreVideoThumbLoader(Uri => InputSteam)
=> UriLoader(Uri => InputSteam)
=> UrlUriLoader(Uri => InputSteam Recur to GlideUrl => InputSteam)
=> HttpGlideUrlLoader(GlideUrl => InputSteam)
=> StringLoader(String => ParcelFileDescriptor Recur to Uri => ParcelFileDescriptor)
=> AssetUriLoader(Uri => ParcelFileDescriptor)
=> UriLoader(Uri => ParcelFileDescriptor)
=> StringLoader(String => AssetFileDescriptor Recur to Uri => AssetFileDescriptor)
=> UriLoader(Uri => AssetFileDescriptor)
过滤完所有 ModelLoader 以后就会分别调用其 buildLoadData 方法前去构建 LoadData。例子中最终只会返回一个 LoadData 其 key 为 url,fetcher 为 MultiFetcher 内部包含两个 HttpUrlFetcher,因为根据上文 StringLoader => HttpUriLoader => HttpGlideLoader 以及 StringLoader => UrlUriLoader => HttpGlideUrlLoader 都满足需求。
最终返回 [url]。
DecodeHelper.getRegisteredResourceClasses
getRegisteredResourceClasses 用于获取所有能转换为目标资源类型的类型
public <Model, TResource, Transcode> List<Class<?>> getRegisteredResourceClasses( |
这个方法挺复杂的主要工作包括:
- 获取当前输入源能转换成的所有类型,对于 String 类型根据 ModelLoader 注册表,可以得出一共可以转换为 InputSteam、ParcelFileDescriptor、AccessFileDescriptor 三种。
- 对于每种可转换类型,分别获取解码后获得的资源类型,根据 ResourceDecoder 注册表,InputSteam 可以被解码成 GifDrawable、 Bitmap、BitmapDrawable;ParcelFileDescriptor 可以被解码成 Bitmap、BitmapDrawable;AccessFileDescriptor 可以被解码成 Bitmap。
- 对于每种解码后资源类型,查询其是否能被转码成目标类型,对于可以转换的(包括强转或者使用转码器)加入到 Result 中进行返回。
最终返回 GifDrawable、Bitmap 以及 BitmapDrawable。
DATA_CACHE
DATA_CACHE 表明从磁盘缓存中读取原始图片资源,对应 DataCacheGenerator 类。根据 runGenerators 的逻辑,跟进其 startNext 方法。
public boolean startNext() { |
这个方法主要是从磁盘缓存中查询是否存在原始图片资源,如果存在再进行解码,这里先跳过,后续分析缓存的时候再看。首次进入该方法由于没有缓存,最终会返回 false。接着会进入下一步。
SOURCE
DATA_CACHE 表明从数据源处获取图片资源,对应 SourceGenerator 类。根据 runGenerators 的逻辑,跟进其 startNext 方法(这里会进行 reschedule 流程,不过还是会调用)。
public boolean startNext() { |
终于到了加载资源的地方了,前面说过这里只有一个 LoadData ,该 LoadData 中会存在一个 MultiFetcher,最里面就是两个 HttpUrlFetcher(Why?),直接看 HttpUrlFetcher.loadData 方法看看其是如何加载资源的。
// HttpUrlFetcher.java |
最终就是通过 HttpUrlConnection 发起请求获取到 InputSteam(响应体),回调 SourceGenerator 的 onDataReady 方法。
public void onDataReadyInternal(Object data) { |
这里又调用了 reschedule ,最终又会重新调用一次 SourceGenerator.startNext 方法。
public boolean startNext() { |
本次进来是 dataToCache 已经不为空了(已经是刚刚请求回来的 InputSteam 了),调用 cacheData 将其缓存下来,而缓存流程为首先获取到编码器,通过查询注册表,编码器对应类为 SteamEncoder ,接着调用 DiskLruCacheWrapper.put 进行缓存。
public void put(Key key, Writer writer) { |
内部使用了 DiskLruCache ,然后通过编码器,将刚刚的响应数据写入到缓存文件中,缓存完毕后又会调用 DataCacheGenerator.startNext 不过这回有缓存了。
public boolean startNext() { |
由于现在原图已经有了缓存,因此会退出上面的 while 循环进入下面的循环,下面的循环会遍历所有能转换 File 的 ModelLoader,经过查询注册表,发现有以下这些。

对每个 ModelLoader 调用 buildLoadData 方法构建 LoadData ,选择第一个不为空的并且存在一条完整加载路径的 loadData 调用loadData.fetcher.loadData 加载数据。那么具体该怎么理解完整加载路径呢?Glide 内部其实是通过 LoadPath 来表示加载路径的,通过分析 DecodeHelper.hasLoadPath 就可以了解。
// DecodeHelper.java |
这里主要是处理了一层缓存,忽略缓存,首先调用 getDecodePaths 去获取所有可以满足条件的解码路径,然后使用其构建 LoadPath。那么什么叫满足条件的解码路径呢?继续来分析 getDecodePaths 方法。
private <Data, TResource, Transcode> List<DecodePath<Data, TResource, Transcode>> getDecodePaths( |
乍一看这段代码好像很难理解,不过举个例子就会很容易理解,首先选择了 ByteBufferFileLoader,因此 dataClass 为 ByteBuffer.class,resourceClass 为 Object.class(默认),transcodeClasses 为 Drawable.class(asDrawable 设置),一条完整的解码路径为,如何从 ByteBuffer 解码成 Object,然后如何从 Object 转码成 Drawable。下面分析代码
注释一获取到所有能将 ByteBuffer 解码成的类(GifDrawable、Bitmap、BitmapDrawable)。
注释二获取到有几种方式能将解码完成的资源(GifDrawable、Bitmap、BitmapDrawable 之一)转码成 Drawable。
注释三获取到支持转换的所有解码器(如支持 ByteBuffer 转换为 GifDrawable)。
注释四获取到支持转码的所有转码器(如支持 GifDrawable 转换为 Drawable)。注意:如果可以直接强转会返回 UnitTranscoder。
经过分析 LoadPath 的意义其实很明确了,其实就是 dataClass => resourceClass => transcodeClass 的所有解码路径集合。
回到上面,由于值选择第一个不为空的并且存在一条完整加载路径的 loadData 调用 loadData.fetcher.loadData 加载数据,因此 DataCacheGenerator.startNext 其实就可以理解成最终调用了 ByteBufferFileLoader.ByteBufferFetcher(resourceClass 为 Object,transcodeClass 为 Drawable),跟进代码。
public void loadData(@NonNull Priority priority, DataCallback<? super ByteBuffer> callback) { |
内部也就是通过 NIO 将数据读取进了 ByteBuffer 中,然后一步步回调到 DecodeJob.onDataFetcherReady,接着不需要管线程判断,因此不管怎么样都会调用 decodeFromRetrievedData 。
// DecodeJob.java |
最终根据 LoadPath 解码并转码资源,获取到最终的资源。对于 ByteBuffer => Object => Drawable 一共有以下几条路径

接下来就开始真正的进行加载了,跟进 LoadPath.load 方法。
// LoadPath.java |
LoadPath 又委托给 DecodePath 进行加载,只要有一个成功那么就直接退出循环,并返回。
public Resource<Transcode> decode(DataRewinder<DataType> rewinder, int width, int height, |
方法主要分为以下三步:
- 解码资源,如 ByteBuffer => GifDrawable
- 解码完成回调 DecodeJob 将解码后的资源缓存
- 转码资源,用于最终显示。
decodeResources
解码资源就是通过解码器进行解码
private Resource<ResourceType> decodeResource(...) throws GlideException { |
遍历所有 Decoder 调用 handle 方法判断是否能解码,如果可以调用 decode 方法真正解码,只要有一个解码器返回成功就退出循环。
对于 ByteBufferGifDecoder
// ByteBufferDecoder.java |
只要不禁用 Gif ,那么最终会通过 HeaderParser 读取文件头,判断是否是 Gif 格式,具体细节如下。
private ImageType getType(Reader reader) throws IOException { |
可以看到通过读取两个字节就能判断是否是 JPEG,通过读取三个字节就能判断是否是 GIF,通过读取四个字节就能判断是否是 PNG。
如果前三个字节为 0x474946 那么就是 GIF 图片,Glide 也提供了选项将 Gif 当做普通图片处理(GifOptions.DISABLE_ANIMATION)
private GifDrawableResource decode( |
具体是如何解码这个 Gif 文件逻辑就不看了,因为这个需要了解 Gif 文件格式(后续有兴趣再看),最终返回了一个 GifDrawableResource 内部包含了 GifDrawable。
对于 ByteBufferBitmapDecoder
// ByteBufferBitmapDecoder.java |
Downsampler 的 handles 方法必定返回 true,继续看 decode 方法。
public Resource<Bitmap> decode(ByteBuffer source, int width, int height, Options options) |
decodeFromWrappedStreams 会通过 BitmapFactory 加载图片,并对图片进行缩放、翻转,代码过于复杂就不贴了。
onResourceDecoded
解码完成后,需要通过 DecodeJob ,回调其 onResourceDecoded 方法。
<Z> Resource<Z> onResourceDecoded(DataSource dataSource, Resource<Z> decoded) { |
方法内部主要做了以下几个操作:
- 应用 Transform,可以通过 RequestOption 设置。
- 检查是否存在编码器可以编码该资源。
- 判断当前资源是否需要进行编码(缓存)。
默认的 DiskCacheStrategy 为 AUTOMATIC ,当加载远程数据(比如,从URL下载)时,该策略仅会存储原始数据,因为下载远程数据相比调整磁盘上已经存在的数据要昂贵得多。对于本地数据,该策略则会仅存储变换过的缩略图,因为即使你需要再次生成另一个尺寸或类型的图片,取回原始数据也很容易。 远程数据存储原始图片,本地数据存储转换后的图片
transcode
应用完 transform 以后,又会对资源进行转码,其实根据转码注册表,也就是 Bitmap 能转化为 Drawable,其它都只能转化为 bytes[]。Bitmap 转换为 Drawable 采用方式为创建一个 BitmapDrawable。
至此资源解码、转换、转码成功,现在又要回到解码前,也就是 DecodeJob.decodeFromRetrievedData 。
private void decodeFromRetrievedData() { |
主要分析下 notifyEncodeAndRelease 方法。
private void notifyEncodeAndRelease(Resource<R> resource, DataSource dataSource) { |
方法内部首先会通知 EngineJob 资源已经准备完毕,然后如果需要缓存那么进行缓存,缓存完毕后清理下资源。重点看看 EngineJob 收到资源完成后做了什么。
// EngineJob.java |
至此图片已经加载完毕,并交付给了 Target。
注:关于硬件位图
注:Glide V3 默认使用 RGB_565 ,Glide V4 默认使用 ARGB_8888。
缓存机制
Glide 分为内存以及磁盘两级缓存,其中内存又分为弱引用缓存以及一个 LRU 缓存,磁盘缓存又分为转换后的资源缓存以及原图缓存,缓存由 DiskCacheStrategy 控制,除原图缓存其它的缓存键都与加载的图片长宽有关。
public abstract class DiskCacheStrategy { |
缓存主要分为以下情况(以加载网络图片为例):
- 无缓存的网络图片加载流程。
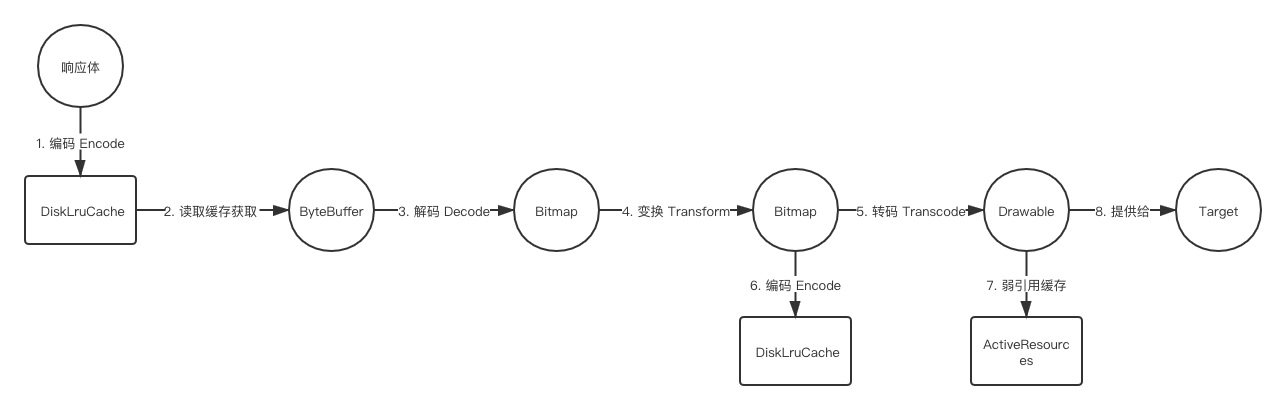
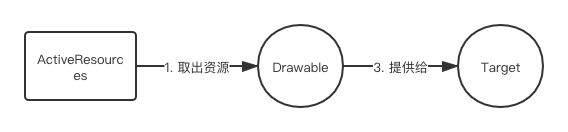
- 有弱应用缓存的网络图片加载流程
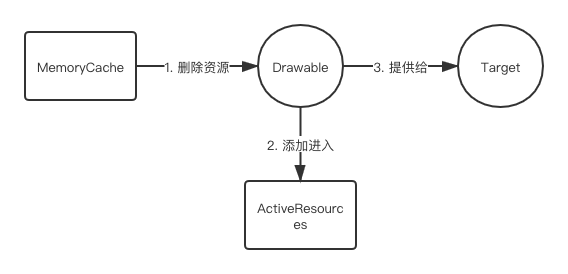
- 无弱引用缓存有 Lru 内存缓存的网络图片加载流程
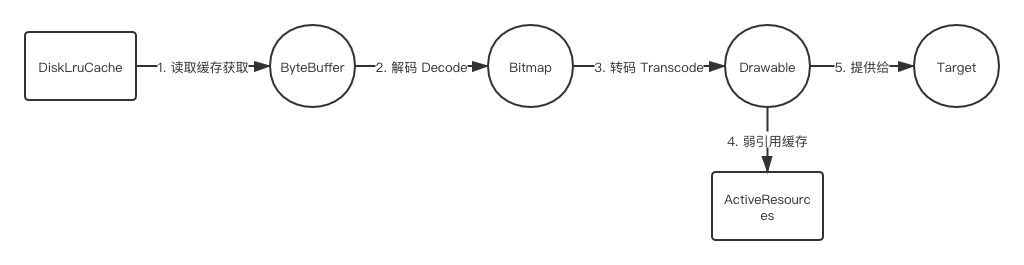
无弱引用缓存无 Lru 内存缓存有 Resource 磁盘缓存
注意:由于缓存的已经是转换过的资源因此不需要再执行 Transform。
无弱引用缓存无 Lru 内存缓存无 Resource 磁盘缓存有原始图片缓存
注意:除了不需要从网络下载,其它流程都一样。
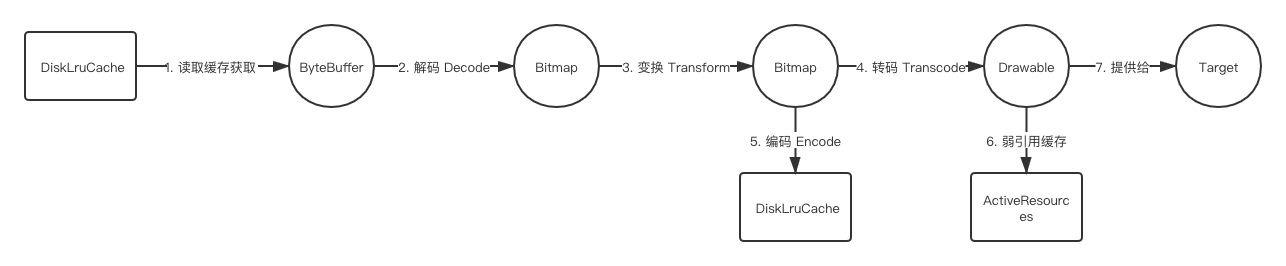
上述五种情况已经涵盖了差不多所有情况,不过有个问题,那就是 Lru 内存缓存的内容是哪里来的,好像没有在上面的图中有所体现?
通过翻阅代码发现 EngineResource 内部含有一个引用计数器,表示该资源现在被使用的数量。
每次调用 into() 加载一个资源,这个资源的引用计数就会加一,如果相同的资源被加载到两个不同的 Target,则在两个加载都完成后,它的引用计数将会为二,当在加载资源的 View 或 Target 上调用 clear() 或者在这个 View 或 Target 上调用对另一个资源请求的 into 方法时该资源引用计数就会减一。
// Engine.java |
如果引用计数器为 0 了以后就会从弱引用缓存中移除,如果资源可以进行内存缓存那么放入 Lru 内存缓存,否则回收该资源。看到这里终于明白了,Lru 内存缓存的内容哪来的,同时 Lru 内存缓存与弱引用缓存不会存在重复资源。
那么为什么需要这个弱引用内存缓存,直接统一管理一个 Lru 内存缓存不好吗?
可能使用弱引用缓存可以杜绝被 Lru 算法删除吧。